
Model and Pipeline Parallelism
Scaling Training for Large Models
In the previous article, we explored how distributed data parallelism can accelerate model training by distributing data across multiple GPUs/nodes. This strategy works perfectly for small to medium-sized models, which can be trained within a single GPU. However, it becomes impossible for models with over a few billion parameters.
Training a model like Llama-2-7b-hf can demand up to 361 GiB VRAM, depending on the configuration (Figure 1). No current enterprise GPU has sufficient VRAM to accommodate such a large model. For instance, the NVIDIA H200 Tensor Core GPU, with “only” 140 GiB of VRAM, falls far short of the requirement.

Alternative approaches are needed to overcome the limitations of data parallelism when dealing with such immense models. Model parallelism and pipeline parallelism address this challenge by distributing the model itself across multiple devices, enabling the training of models far larger than any single GPU could handle.
Model Parallelism
Simple model parallelism splits a neural network across multiple devices, assigning layers or sequences of layers to each. During the forward pass, activations are transferred between devices, and the backward pass similarly transfers gradients across device boundaries (see Figure 2 for an illustration). This approach allows training models exceeding a single device’s memory capacity but introduces communication overhead at each layer transition.

A key limitation of the naïve model parallelization is low device utilization. Due to the sequential nature of forward and backward propagation, only one device computes at a time, while others remain idle, resulting in “pipeline bubbles” where most time is spent on communication and waiting. This effect is illustrated in Figure 3. For a model split across N devices, each device is active only about 2/N of the time, excluding communication overhead.
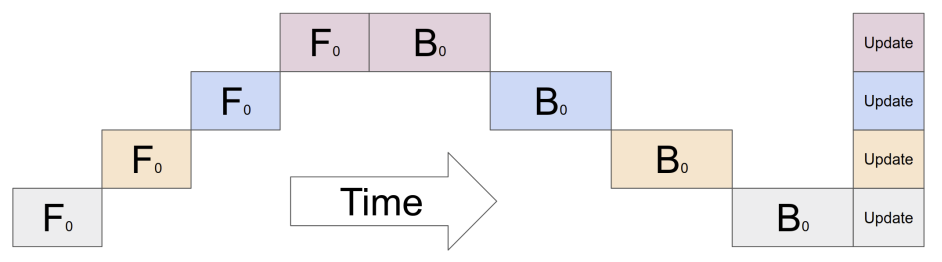
Additionally, naïve model parallelism imposes uneven memory utilization, disproportionately burdening devices responsible for the initial layers (e.g., device 0). These devices must retain all activations for the entire mini-batch throughout the forward and backward passes. Since activations are sequentially propagated forward and required in full for gradient computation during the backward pass, they remain in memory until the backward pass concludes.
Pipeline Parallelism
GPipe
The GPipe algorithm (published in 2019) improves upon naïve model parallelization by splitting each minibatch into microbatches. Rather than waiting for an entire minibatch to finish on one device before proceeding, it immediately sends the output of the first microbatch to the next device, keeping all devices busy in parallel. This pipelining reduces idle time compared to purely sequential processing—see Figure 4 for an illustration.

Each device computes partial gradients for every microbatch and sums them locally. Once all microbatches in a minibatch are processed, the final gradients on each device correspond exactly to the gradients of the entire batch. Although floating-point non-associativity prevents bitwise equivalence, this procedure is mathematically the same as running the minibatch in a purely sequential manner.
To further reduce memory consumption, the GPipe algorithm uses re-materialization (activation checkpointing). During the forward pass, each device caches only the activations at the partition (device) boundaries. During backpropagation, the k-th device recomputes the composite forward function Fk for its intra-layers, reducing the need to store every intermediate activation. As a result, the peak activation memory requirement drops from O(N×L) to:
Where N is the minibatch size, L is the total number of layers, K is the number of partitions, and N/M is the microbatch size. This trade-off lowers memory usage at the cost of increased computational overhead, as devices must recompute intra-forward activations during backpropagation.
Such pipelining still has a “bubble” overhead, which can be expressed as:
The bubble exists because pipelining inherently requires sequential dependency - later devices must wait for outputs from earlier devices, creating unavoidable idle time during pipeline fill-up and drain phases. This overhead becomes negligible with sufficient microbatches (M ≥ 4K) since the steady-state parallel processing dominates the total execution time.
PipeDream
PipeDream is an asynchronous pipeline-parallel training approach, developed around the same time as GPipe but with a distinct design. It continuously injects multiple microbatches into the pipeline and begins each microbatch’s backward pass as soon as the final stage completes its forward pass—unlike GPipe, which waits until all forward passes finish. Figure 5 illustrates this. Once the pipeline is fully saturated, devices remain busy, and PipeDream can discard cached activations earlier because they are only needed until each microbatch’s backward pass begins. In this respect, PipeDream uses less memory than GPipe, where all microbatches stay “in flight” until the full minibatch’s forward pass is done.

However, PipeDream’s asynchrony introduces weight staleness because the backward pass might otherwise use different weights than those from its forward pass. To address this, PipeDream employs weight stashing, storing an exact weight version for each microbatch’s forward pass so the same version can be reused during the backward pass. Figure 6 shows how each microbatch sees consistent weights, preserving the correctness of gradient updates.

PipeDream's asynchronous 1F1B (one forward pass, then one backward pass per stage) scheduling flexibility allows for data parallelism through stage replication, where multiple replicas process different microbatches in parallel. Such an approach combines model parallelism (splitting layers across GPUs) and data parallelism (replicating partitions) to boost throughput, using dynamic programming to optimize computation and communication balance. Compared to GPipe's more synchronous design that requires all microbatches to complete each pipeline phase before proceeding, PipeDream may achieve higher hardware utilization and faster training at the cost of increased complexity and higher memory overhead from storing multiple weight versions.
Conclusions
Approaches like GPipe and PipeDream illustrate how high-performance computing (HPC) principles—such as pipelining, re-materialization, and interleaving—can be adapted for deep learning to reduce idle time, improve memory efficiency, and ensure scalable performance. By carefully managing trade-offs between synchronization overhead, memory consumption, and computational cost, these techniques enable the training of multi-billion-parameter models that were once out of reach. From weight stashing to advanced partitioning algorithms, the ultimate goal parallels HPC’s longstanding pursuit of maximizing device throughput while minimizing idle time.
Having now explored data parallelism, model parallelism, and pipeline parallelism, we are left with a few remaining frontiers: tensor parallelism and fully sharded data parallelism. In our next article, we will delve into how these methods further advance our ability to train ever-larger models on modern computing architectures.