
Maintainable Machine Learning Pipelines
Important Parts to Consider

Rapid and reliable feature iteration is often key to the success of machine-learning projects. Yet, achieving such a development setting in practice usually proves challenging. From experimentation to model serving - there are a number of issues that can quickly appear if core development concepts are disregarded. Inconsistent data between experiments, non-portable training scripts confined to a single developer's machine, temporary manual performance evaluations that become permanent, mismatched inference environments due to irreproducible experimental setups, etc., are all part of the usual machine learning project pitfalls. Whether due to insufficient long-term planning or lack of knowledge of how to do things better, these issues can significantly hinder productivity.
This article will try to surface important concepts when developing ML pipelines. The main focus areas will be reproducibility, artifact tracking and automation. We'll build a pipeline from the ground up and explain the reasoning behind each step. All code examples are available in the ml-workflows repository to help you follow along and conduct your own experiments. Hopefully, by the end of this article, you'll discover useful concepts/ideas that can help you design better workflows.
Introduction
Before we get into the technical implementation, we should briefly cover the frameworks/platforms that we will be using: Kubeflow Pipelines and Google Cloud Platform's Vertex AI. Disclaimer — this article doesn't advocate for Kubeflow Pipelines as the definitive framework for developing machine learning workflows (alternative frameworks will be provided in the appendix), nor does it endorse Vertex AI as the optimal managed platform. The choice of these specific tools stems from pragmatic reasons — namely, their immediate availability in my existing setup or compatibility with it.
When selecting frameworks and managed platforms, consider more than just possible technical “features” — team size and engineering capacity can play a significant role here, too. For smaller teams, self-managing a Kubernetes cluster and Kubeflow Pipelines can drain productivity, making managed platforms a better fit, as they allow focus on business goals rather than infrastructure. Larger teams with more resources may benefit from the control offered by self-managed systems. While infrastructure costs matter, they typically concern only larger companies with the necessary engineering capacity and computing load, whose costs become noticeable compared to engineering salaries. The key is to balance control/costs with productivity, ensuring infrastructure choices enhance, not hinder, your team.
Lastly, I would like to focus not on the specific tools or services but on the underlying engineering concepts and designs that ensure effectiveness and robustness. While frameworks and platforms may evolve or become obsolete, solid engineering principles will endure and continue to be relevant.
Kubeflow Pipelines
Kubeflow Pipelines (KFP) is a framework1 for building and deploying machine learning workflows using Docker containers. Using the KFP Python SDK, developers can define:
Components: Containerized individual steps of the workflow, each encapsulating a specific task such as data preprocessing, model training, or evaluation. These components are self-contained and reusable across different pipelines.
Pipeline: The overall definition of the machine learning workflow, combining all components and specifying their interactions, data flow, and execution order.
These definitions are then compiled into an intermediate representation in YAML format, which serves as a portable, language-agnostic description of the pipeline. The compiled YAML can then be deployed to any KFP-conformant backend. This approach ensures that workflows defined with KFP can be executed across different environments without modification, enhancing their portability and reproducibility.
Vertex AI
Vertex AI is Google Cloud Platform's unified machine learning platform. It provides tools and services for the entire ML lifecycle, from data preparation to model deployment and management. Vertex AI integrates various ML services and features under a single interface. One of these services is Vertex AI Pipelines - a fully managed and serverless workflow orchestration tool built on top of Kubeflow Pipelines, functioning as a KFP-conformant backend. This managed service eliminates the need for users to provision or manage the underlying infrastructure, automatically handling scaling, maintenance, and upgrades. Vertex AI Pipelines also offers built-in features for artifact lineage tracking and experiment management, while seamlessly integrating with other Vertex AI services.
Problem Statement
Let’s assume we are running a renewable energy company that seeks to optimize solar and wind farm operations across diverse geographic locations. By implementing an AI system that can automatically recognize weather conditions from images captured by on-site cameras, we can predict energy output more accurately and adjust operations in real-time. This weather recognition capability would enable more efficient resource allocation and improve overall energy production forecasting.
For this problem, we've acquired a “Weather Image Recognition” dataset as an initial dataset that we believe will meet our needs. Our goal is to create a model capable of predicting 11 distinct weather conditions: dew, fog/smog, frost, glaze, hail, lightning, rain, rainbow, rime, sandstorm, and snow. This diverse range of weather phenomena will allow our AI system to provide comprehensive insights for optimizing our renewable energy operations.
The aim of our project is to develop a robust model training pipeline that researchers and engineers can easily reuse with different runtime parameters. It should accommodate varying data sources (if somebody decides to enhance the initial dataset), data splits, random seeds, training epochs, etc. The pipeline should guarantee reproducibility and ease of artifact tracking, as well as a high level of automation.
Designing the Pipeline
In this section, we will build our machine-learning pipeline step by step. We'll begin with the "Data Preparation" component, move on to the "Model Training" component, and finish with the "Model Evaluation" component. As mentioned earlier, we will use the KFP SDK to define both the components and the pipeline.
Each component will follow the standard Python project structure outlined in the "Python Project Management Primer," and the Docker images for each component will be built using the optimization techniques from "Optimizing Docker Images for Python Production Services."
Finally, I’ll include links to the GitHub repository for the component/pipeline code and add pictures instead of code snippets in the article. Substack currently doesn’t support code highlighting, making longer code harder to read.
Data Preparation Component
For this problem, we could write the data preparation component as follows:

A few comments about the component:
The component uses kfp Output to define output artifacts that can be tracked and consumed by downstream components. In this case, it outputs the data split information for training, validation, and test datasets.
We also specify an output artifact of type Metrics to track the number of classes assigned to each dataset.
Other function arguments, such as
data_bucket,random_seedetc., are just simple parameters passed to the component function.Within the component, stratified sampling is applied to maintain class distribution. A fixed random seed ensures that the results are reproducible if needed.
An important note about the data_bucket data source: in this case, we assume it is an immutable cloud storage bucket. Using a "live" storage bucket instead can lead to reproducibility issues, as new objects might be added or existing ones modified or deleted. This makes it difficult to ensure the reproducibility of a specific pipeline run and to recover its source dataset if needed. If you plan to use “live” storage, it’s recommended that you clone it, make the clone immutable, and use that one instead to ensure reproducibility.
Model Training Component
The model training component can be implemented as shown below:

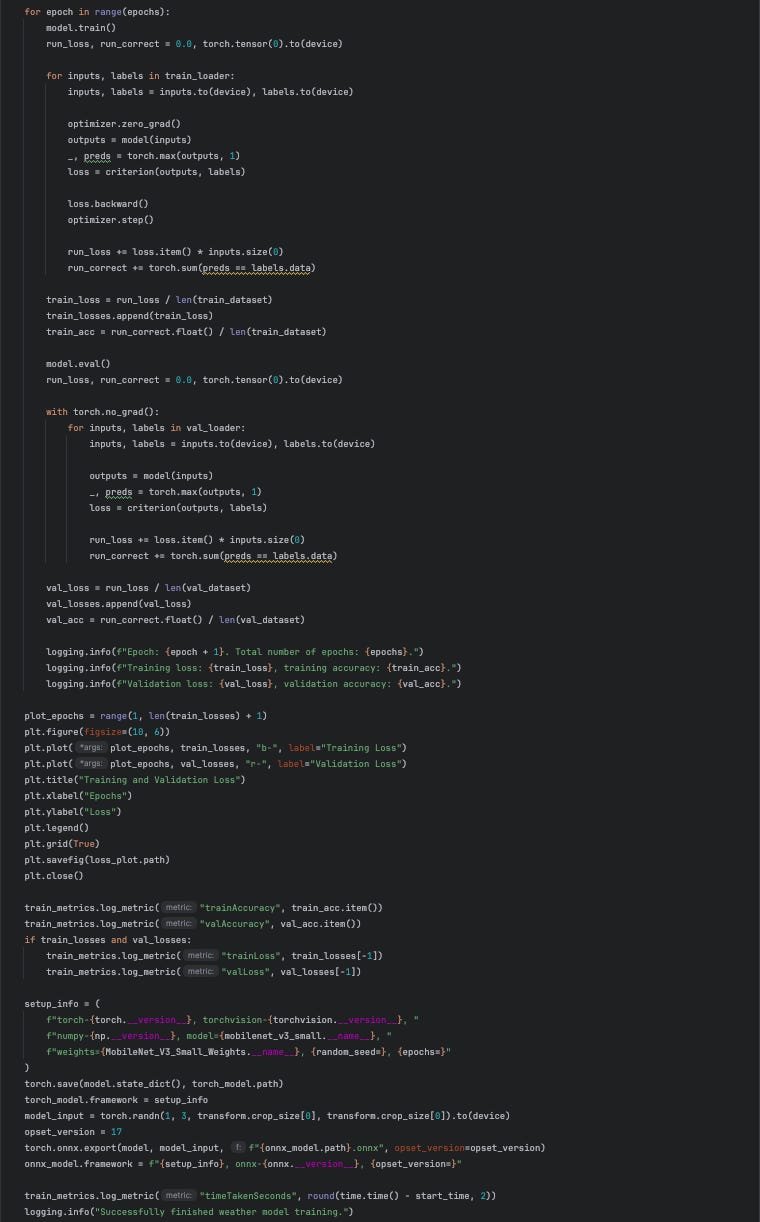
Comments about the model training component:
The component uses kfp Input to define the input artifacts it consumes, which were produced upstream. In this case, these are the
train_split_infoandval_split_infoartifacts that were produced by theprep_datacomponent.Before training begins, we ensure reproducibility by fixing random seeds and enabling deterministic algorithms in PyTorch.
The training process follows a standard fine-tuning approach. We use the
mobilenet_v3_smallmodel, freezing all layers except for the final classification layer, which acts as the new model head for this specific task.During training, we track both training and validation losses and accuracy. Once training is complete, these metrics are saved as an
Metricsartifact. Additionally, we save the loss function plot, the PyTorch model’s state dictionary, and the ONNX model. Exporting to ONNX simplifies deployment if the PyTorch model performs well in evaluation, allowing for direct use in production environments.
In this example, since we used a small model and only fine-tuned the head, there was no significant need for GPU usage. However, for larger models or if more layers require fine-tuning, a GPU-accelerated runtime environment becomes essential. This can be easily achieved by using pre-built CUDA wheels for PyTorch. Additionally, the GCPs create_custom_training_job_from_component function can simplify the process of configuring GPU accelerators for the pipeline component.
Model Evaluation Component
Lastly, the model evaluation component can be defined as shown below:

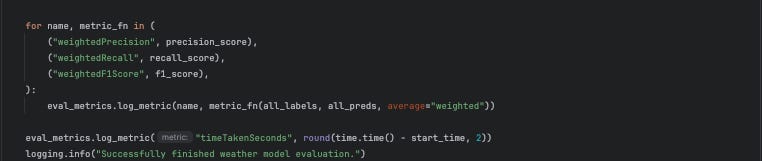
There isn’t much that’s unique about the evaluation component compared to the previous ones. At the end of the evaluation, this component outputs an Metrics artifact containing the weighted precision, recall, and F1 score, as well as the ClassificationMetrics artifact which contains the confusion matrix plot.
Pipeline Definition
Once we have all the desired component functions, we can define the pipeline itself:


The current implementation depends on several environment variables:
KFP_REPOSITORY: This is the artifact registry repository in the "Kubeflow Pipelines" format. The compiled pipeline representation will be uploaded here.STAGING_BUCKET: A cloud storage bucket where the pipeline will store its runtime information and artifacts.PREP_DATA_DOCKER_URI,TRAIN_MODEL_DOCKER_URI,EVAL_MODEL_DOCKER_URI: These are the URIs of the pre-built Docker images for each component. During the pipeline run, these images will be fetched and used as runtime environments for the corresponding components.
The create_component_from_func function converts a Python function into a Kubeflow Pipelines component, specifying the Docker image to be used as its runtime environment.
With the pipeline defined, the final step is to run poetry run pipeline. This will upload the pipeline to the specified repository, making it ready for use.
Creating Pipeline Run
After the pipeline is uploaded to the repository, creating a pipeline run from it is as simple as following the official Vertex AI documentation:


The resulting pipeline run diagram:

By default, component result caching is enabled, meaning components are not re-executed unless their input parameters or the components themselves are modified. For example, this would allow for adjustments to the evaluation code without the need for time-consuming retraining.
In the provided diagram, we can easily inspect the artifacts and check their values:
Training loss plot (inside
STAGING_BUCKET):

Confusion Matrix (rendered directly within the diagram):

Evaluation Metrics (shown directly within the diagram):

Comparing Different Runs
With this setup, we can also get side-by-side comparisons for free if we add pipeline runs of interest to the vertex ai experiment:


At this stage, the entire team can use our pipeline to run automated experiments with different parameters, aiming to find a more effective model. If needed, further improvements could include parameterizing the model choice for fine-tuning in the pipeline and the training component.
Conclusions
In this article, we developed a model training pipeline using Kubeflow Pipelines and Vertex AI, emphasizing key concepts like reproducibility, artifact tracking, and automation. By integrating these principles into our pipeline design, we ensured consistency across different experiment runs and guaranteed reproducibility when needed for specific experiments. Additionally, the pipeline was automated from data fetching to model evaluation, featuring an API and UI that are simple enough for non-domain experts to use.
Appendix
Other alternative frameworks for building machine learning workflows besides Kubeflow Pipelines:
The official documentation refers to it as a "platform," but this term is debatable. One could argue that Kubeflow or even Kubernetes is the actual platform in this context, and Kubeflow Pipelines is a framework for building machine learning workflows on top of Kubeflow/Kubernetes.