
Tensor and Fully Sharded Data Parallelism
How Trillion Parameter Models Are Trained

In previous articles, we covered data, model, and pipeline parallelisms. Data parallelism offers excellent bandwidth utilization and works well when the entire model fits into a single device’s memory. Pipeline parallelism provides a strategy to train models that exceed device memory by splitting them across different stages, while still achieving relatively high utilization of each processor.
However, for extremely large models, pipeline parallelism alone is insufficient. While pipeline bubbles can reduce training efficiency, the sheer size of a single layer can become an even greater bottleneck. For instance, let us consider one MLP1 layer in a GPT‑4‑scale model, configured with a hidden size (d_model) of 16,384 and a feedforward size (d_ff) four times larger. That setup has approximately 4 x 16,384 x 16,384 ≈ 1.07 billion parameters in just one layer. Training this layer in FP32 precision demands around 4.29 GB for the parameters themselves, another 4.29 GB for the gradients, and 8.58 GB for the optimizer states when using Adam—totaling roughly 17.16 GB of memory. Such a large memory footprint already exceeds the capacity of many consumer-level GPUs. While enterprise GPUs may handle these demands, they too can be overwhelmed by ever-growing model scales. But most importantly, even if a single GPU can accommodate such massive layers, parallelizing their computations can still yield better throughput and efficiency.
So, how do we train a model with a trillion parameters or more? To tackle such a challenge, we need to look into tensor and fully sharded data parallelisms, which are more advanced techniques for scalable training.
Tensor Parallelism
Tensor parallelism (TP), first introduced for large-scale model training in “Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism” (Shoeybi et al., 2020, arXiv), is a technique that distributes the operations of a single layer across multiple GPUs. Consider the feed-forward component of a transformer’s MLP block: typically, an input vector X is multiplied by a weight matrix A to produce an output Y, which is then passed through a non-linear activation GeLU(⋅)2. Rather than storing the entire A on a single GPU, tensor parallelism partitions A into smaller blocks (e.g., A1, A2), each handled independently by a different GPU. However, the way in which these matrices are split matters. A naive approach might split the weight matrix A across its rows while partitioning the input X across its columns:
The downside is that this setup imposes a synchronization point before the non-linear activation function, because partial results must be combined before applying GeLU(⋅):
Synchronization points are expensive and can significantly reduce training throughput; hence, it’s best to minimize them whenever possible. An alternative is to split A along its columns:
This design lets each GPU independently apply the non-linear activation to its local output, thereby avoiding the extra synchronization step and improving overall efficiency (see Figure 1a).
In Megatron-LM, tensor parallelism is extended to self-attention by splitting the Key (K), Query (Q), and Value (V) matrices column-wise, so each GPU handles a subset of the attention heads and performs the corresponding matrix multiplications locally (see Figure 1b). This eliminates immediate cross-GPU communication during attention, as each GPU only needs the portion of input relevant to its heads.

Meanwhile, the second linear layer of the MLP and the output linear layer after self-attention are split row-wise. This design leverages the fact that each GPU already holds the complete output for its assigned attention heads—by concatenating those outputs locally, each GPU can process its own subset of rows without having to communicate with other GPUs. In other words, row-splitting avoids forcing another cross-GPU synchronization step.
The necessary communication is handled using two “conjugate” operators: f, which performs an all-reduce in the backward pass and acts as an identity function in the forward pass, and g, which performs an all-reduce in the forward pass and acts as an identity function in the backward pass. This design ensures only two all-reduce operations occur overall in the forward pass and two in the backward pass, thereby keeping synchronization overhead low (see Figure 2)

Much of Megatron-LM’s TP strategy revolves around maximizing GPU independence to minimize communication. Each GPU handles its own computations and parameter updates, with communication limited to essential all-reduce operations. This approach reduces bottlenecks and keeps GPUs fully utilized.
Fully Sharded Data Parallelism
Fully Sharded Data Parallelism (FSDP) is a memory-efficient technique designed to train massive models by distributing memory usage across GPUs. First introduced in the paper “ZeRO: Memory Optimizations Toward Training Trillion Parameter Models” (Rajbhandari et al., 2020, arXiv), FSDP extends traditional data parallelism by sharding model parameters, gradients and optimizer states. Unlike conventional distributed data parallelism (DDP) approaches, where each GPU stores a full copy of the model, FSDP ensures each GPU holds only a fraction of the model (shard), significantly reducing per-device memory requirements while preserving training efficiency. FSDP achieves this through three key phases of partitioning:
Optimizer State Partitioning (P_os): Optimizer states (e.g., momentum, variance) are divided across N_d GPUs, with each storing and updating only 1/N_d of the total. This partitioning significantly reduces memory usage by lowering the per-GPU optimizer state requirements. After each training step, an all-gather operation synchronizes the updated parameters across all data-parallel processes, ensuring consistency.
Gradient Partitioning (P_g): Gradients are sharded across GPUs during backpropagation. Gradients for each parameter partition are reduced via reduce-scatter to the responsible GPU. Once the full gradients are no longer needed, they are released, minimizing memory overhead for each shard.
Parameter Partitioning (P_p): Model parameters are split across GPUs, each storing 1/N_d of the total. Required parameters from other GPUs are broadcast during training. This adds ~1.5x communication overhead but delivers substantial memory savings.
An intuitive way to understand FSDP is by comparing it to traditional distributed data parallelism (DDP) (see Figure 3). In DDP, each GPU stores a complete copy of the model and processes a portion of the data. Gradients are averaged across all GPUs using an all-reduce operation, ensuring that every GPU updates an identical model copy.
FSDP, in contrast, distributes not just the data but also the model itself, with each GPU responsible for only a shard of the parameters, optimizer states, and gradients. To perform a forward pass, an FSDP GPU temporarily gathers the full model weights from other GPUs via an all-gather operation (see Figure 4).
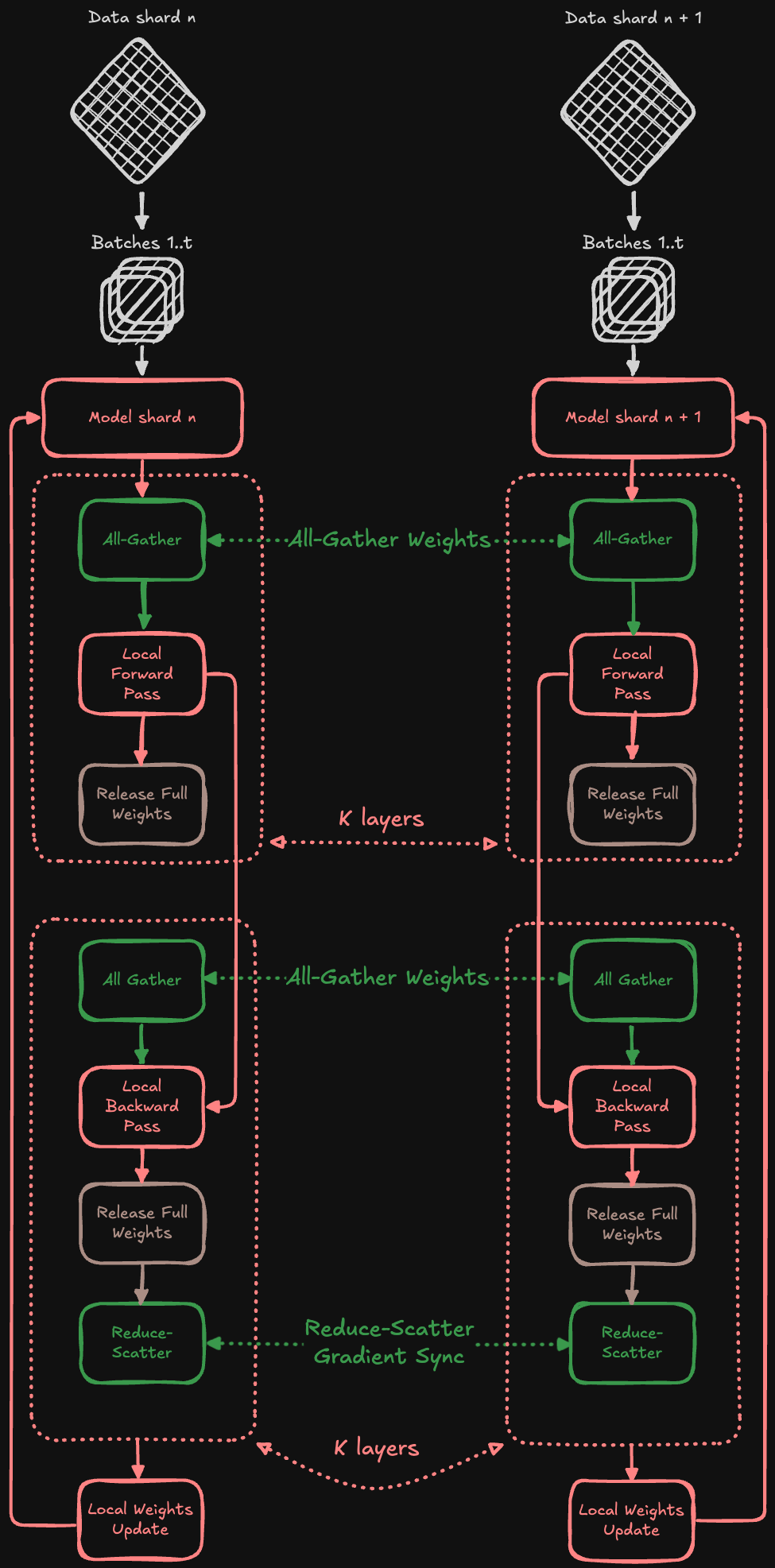
Before the backward pass, the necessary weights are also gathered through an all-gather operation. After the backward pass, a reduce-scatter operation averages and distributes gradients, ensuring each GPU updates only its local portion of the model. Crucially, the reduce-scatter and all-gather operations mirror the DDP's all-reduce, allowing FSDP to shard data and the entire model and optimizer states, saving memory (see Figure 5).

Unlike DDP, where all GPUs maintain and update full model copies, FSDP synchronizes only model shards. Full model assembly occurs temporarily through all-gather operations, solely when required for computation.
The effectiveness of these memory optimizations is dramatically illustrated in the original paper. Figure 6 highlights the significant reduction in memory consumption achieved by applying these techniques.

Despite the significant reduction in memory footprint, FSDP maintains high GPU utilization. This is because the core computations remain unchanged, and the communication overhead introduced by FSDP’s optimizations, such as the reduce-scatter and all-gather operations, is carefully overlapped with computation. Furthermore, by enabling larger batch sizes due to reduced memory usage, FSDP can improve the arithmetic intensity and thus better utilize the computational power of each GPU, often resulting in super-linear scaling as the number of devices increases.

Combining Types of Parallelism
Distributed training parallelism can be broadly classified into two orthogonal approaches: data parallelism and model parallelism. Each operates independently, with unique implementations and characteristics tailored to specific training requirements.
Data parallelism encompasses two primary implementations: naive data parallelism, where each processor maintains a complete copy of the model, and fully sharded data parallelism (FSDP), which, although more nuanced in its implementation, is fundamentally a data-parallel approach.
Model parallelism, on the other hand, includes five main variants: naive model (which operates with sequential forward and backward passes), pipeline, tensor, sequence and expert parallelisms.
These parallelism techniques can be combined to further enhance distributed training throughput. For example, in the paper “Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM” (Narayanan et al., 2021, arXiv), the authors introduced PTD-P, a combination of pipeline, tensor, and data parallelism, which allowed them to train a trillion parameter model. The authors claimed this approach demonstrated better scaling properties than the ZeRO-33 approach without model parallelism. While the fairness of such a comparison may be debatable, the key takeaway is that the PTD-P approach successfully trained an enormous model, achieving 502 petaFLOP/s across 3,072 GPUs with a per-GPU throughput of 52% of the theoretical peak.
FSDP can also be combined with model parallel approaches - for example tensor parallelism (TP), which can be beneficial in specific scenarios. This advanced strategy is supported by the NVIDIA NeMo Framework, which quite clearly explains when such a combination is desired:
Using FSDP with TP can be helpful when the model doesn’t have sufficient parallelism to deploy on a large-scale training system with the data-parallel mapping. For example, running a model with the global batch size of 1024 on 2048 GPUs. Also, TP enables FSDP feasibility by reducing the model state size and the activation size per GPU, thus lower the FSDP communication overhead and the activation memory overhead.
Conclusions
Combining multiple distributed training techniques, such as pipeline, tensor, and data parallelism (PTD-P), or fully sharded data parallelism with tensor parallelism, unlocks the full potential of massive GPU clusters. These strategies address memory and communication challenges, enabling efficient scaling and training of ever-growing models.
ZeRO-3 refers to the ZeRO algorithm with all three types of partitioning enabled: parameters, gradients, and optimizer states.